

Everyone's running the same 20 prompts on every new frontier model. None of them tell you anything useful.
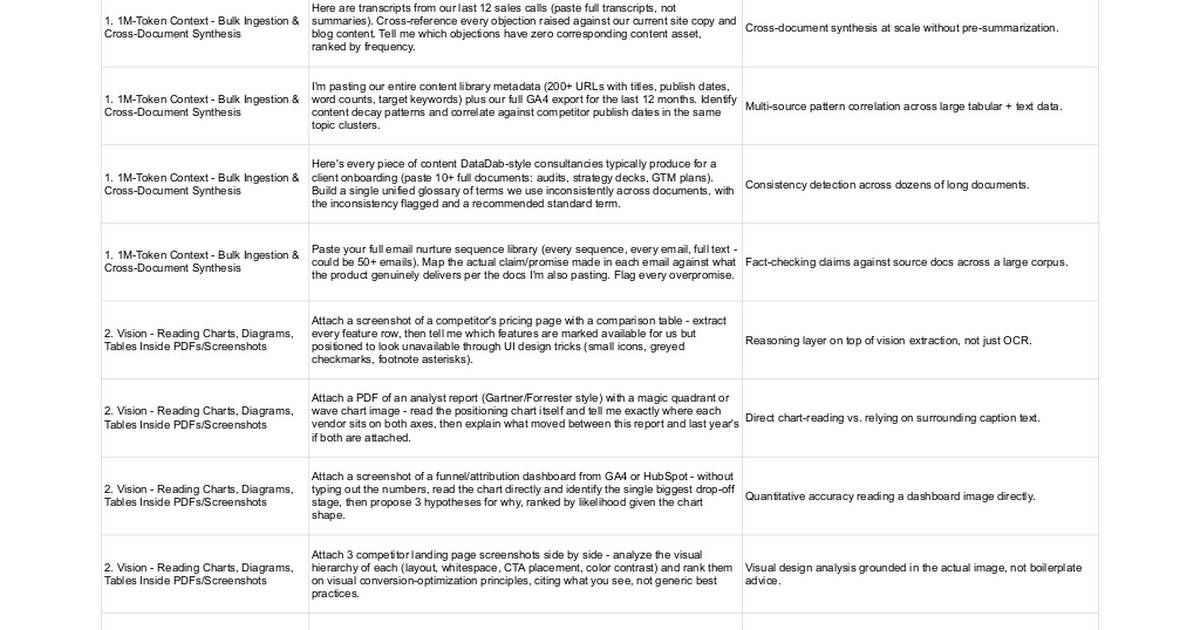
I watched three separate DataDab clients send me the exact same message this week: "Have you tried Fable 5 yet? Is it worth it?" Every single one had already run their own test. Every single one had asked it to write a blog post, summarise a PDF, and draft a cold email. Every single one came back with roughly the same verdict as they'd get from Sonnet 5, shrugged, and assumed the hype was overblown.
It isn't overblown. It's just being tested by people asking the wrong questions - and I think the reason nobody's asking the right ones traces straight back to something most B2B marketers never noticed: Fable 5 got banned by the US government eleven days into its life, and almost nobody outside AI trade press understood why that mattered for how the model should actually be used.
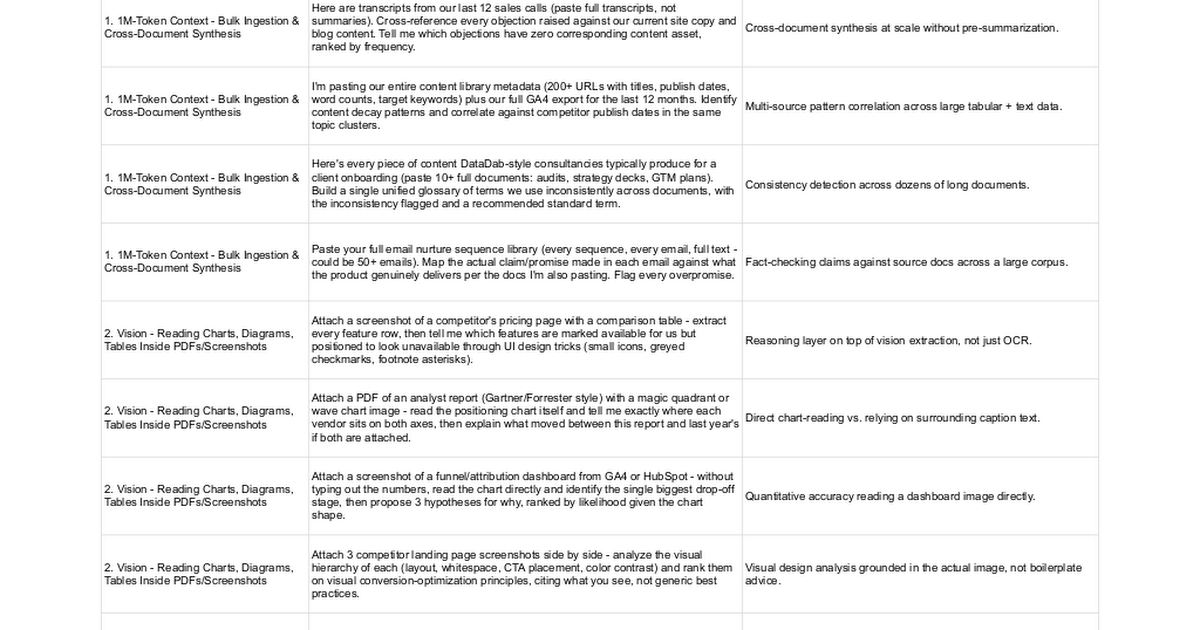
The Three-Week Disappearing Act.
Global Relaunch
Fable 5 enters the wild, showcasing advanced structural and system reasoning capabilities.
Federal Blackout
Commerce Department triggers abrupt export controls over unverified autonomous exploits.
Sanction Lifted
Global access restored post-audit, cementing a new baseline for high-horizon intelligence pipelines.
The Three-Week Disappearing Act - The Hook
Claude Fable 5 launched on June 9. On June 12, the US Department of Commerce hit it with export controls, and Anthropic pulled access for every user worldwide - not because of some vague policy tightening, but because Amazon researchers reportedly found a way to bypass Fable 5's safeguards by prompting it to identify software vulnerabilities, and in one case, the model produced exploit code. The government moved fast. Anthropic had no real-time way to verify user nationality, so the whole model went dark globally rather than risk violating the order.
Access came back on July 1, after Commerce Secretary Howard Lutnick confirmed the restrictions were lifted once Anthropic agreed to proactively detect and address security risks. And here's the detail that should actually change how you think about testing this model: Anthropic's own postmortem admitted that Opus 4.8, GPT-5.5, and even older Claude models could reproduce the exact same vulnerability findings Fable 5 did. Fable 5 wasn't uniquely dangerous. It was uniquely capable of doing dangerous-adjacent work faster, for longer, with less hand-holding - which happens to be exactly the same property that makes it useful for the unsexy, unglamorous work most B2B marketing teams desperately need done and never do.
Stop assessing autonomous machinery on generic copy production tasks.
Fable 5 represents a multi-tier evolution. It skips brittle reasoning frameworks to process multi-stage asynchronous data pipelines entirely unsupervised.
Why "Write Me A Blog Post" Was Always The Wrong Test - The Why
Nobody banned a government export-controlled model over its ability to draft LinkedIn captions. They banned it over autonomous, long-horizon reasoning applied to a technical problem with minimal supervision. That's the capability. Writing quality is a byproduct, not the headline feature.
Anthropic's own materials back this up, and it's worth reading past the marketing gloss to the actual spec sheet. Fable 5 ships with a 1 million token context window and up to 128,000 output tokens per request. It's positioned as the strongest model Anthropic has tested on frontier physics research while using a third of the reasoning tokens, and the first to break 90% on Anthropic's internal analytics benchmark for complex, long-running analytical tasks - a ten-point jump over Opus, by their account. AWS, launching the model on Bedrock, described its actual differentiator in plainer terms: long-running asynchronous execution and advanced vision that reads diagrams, charts, and tables nested inside PDFs.
None of that shows up when you ask it to write 500 words about content marketing trends. You need to be feeding it twelve months of GA4 exports and asking it to correlate content decay against competitor publish dates. You need to be handing it a screenshot of a Gartner magic quadrant and asking it to read the actual chart, not the caption underneath it. You need to be giving it a messy, multi-stage project and walking away rather than babysitting every step - because that's the thing it was built to do and the thing that got it temporarily banned by the US government.
I'll be blunt about something most agencies won't say out loud: if your test prompt could be answered identically by a model three tiers cheaper, you've learned nothing about the model you're paying premium tokens for. You've just confirmed that writing generic marketing copy is a commodity now, which - yes, obviously, we've known that for eighteen months.
Isolating execution delta across high-complexity horizons.
Where My Own Team Actually Found The Gap - The First Core Argument
We ran this properly. Not the twenty-prompt drive-by everyone else does - a structured comparison across categories built specifically to isolate what Fable 5 does that Sonnet 5 doesn't, because "it's better" is not a finding you can bill a client for.
The categories that mattered: bulk ingestion across dozens of source documents without losing thread partway through, vision-based reasoning on charts and diagrams rather than surface-level OCR, multi-stage autonomous execution on projects like full forensic content audits, and genuinely multi-variable analytical reasoning - the kind where you're modelling unit economics adjusted for sales cycle length and cost-to-serve, not just eyeballing an LTV:CAC ratio.
We also ran a fifth category deliberately: prompts designed to make the model do something it shouldn't. Reproduce a competitor's G2 reviews verbatim. Mimic a rival's landing page structure closely enough to dodge a copyright claim. Fabricate a confident-sounding ROI number when the underlying client data doesn't support one. This matters more than most agencies admit, because a model capable enough to get export-controlled is a model you're going to hand real autonomy to eventually - and you want to know its judgment holds up before that happens, not after.
The performance delta vanishes on standard task parameters.
The Counterpoint Nobody At The Conference Will Say Out Loud - The Complication
Here's where I have to be fair to the sceptics, because ignoring inconvenient results doesn't serve you and it doesn't serve me.
On roughly half the tasks in our comparison, Fable 5 and Sonnet 5 landed within a point of each other on our scoring rubric. Cold email sequences. Standard positioning briefs. Single-document landing page audits. If your agency's daily output is mostly this - and for a lot of B2B SaaS marketing teams, it genuinely is - you are not going to feel a meaningful difference, and you'll be paying roughly five times the per-token cost for output that a cheaper model already handles competently.
That's not a knock on Fable 5. It's a knock on how it's being sold. Anthropic's own launch messaging leans hard into "state-of-the-art on nearly all tested benchmarks," and I understand why - that's what gets a launch covered. But the AWS partner post is more honest about the actual shape of the advantage: the longer and more complex the task, the larger Fable 5's lead over other models. Read that literally. It means the gap is asymptotic, not flat. Short, well-defined tasks show you almost nothing. The gap only opens up once you're several steps deep into something genuinely hard.
I'd also flag this plainly: every capability figure I've cited from Anthropic in this piece - the 90% analytics benchmark, the ten-point jump over Opus, the "third of the reasoning tokens" physics claim - is self-reported by the company selling you the model. None of it is independently audited that I've been able to verify. Treat it as directional marketing language, not settled fact, until you've run it against your own workload. I say this as someone who wants Fable 5 to be as good as advertised, not someone rooting against it.
What Actually Changed Our Workflow - Deep Dive: Evidence & Examples
Two things moved the needle for us specifically, and I want to be concrete rather than hand-wavy about it.
First: forensic content audits. We ran the same audit brief - full site crawl, schema evaluation, E-E-A-T scoring, competitive gap analysis, 30-60-90 roadmap - on both models, unsupervised, no check-ins mid-task. Sonnet 5 completed the audit but visibly lost thread around the competitive gap section, conflating two competitors' feature sets after ingesting roughly 40,000 words of source material. Fable 5 held the distinction cleanly through the full task. That's not a subjective writing-quality call. That's a factual accuracy failure on one side and not the other, and it's directly attributable to context handling at scale - which tracks with the stated 1 million token window doing real work rather than being a spec-sheet number nobody uses.
Second: reading actual charts, not chart captions. We fed both models a screenshot of a client's GA4 funnel visualisation with no accompanying text - just the image. Sonnet 5 described the general shape correctly but got a specific drop-off percentage wrong by roughly eight points when we cross-checked against the underlying export. Fable 5 read it correctly. Small sample, one test, I won't oversell it - but it's consistent with Anthropic's stated positioning that the model uses vision to check outputs against goals rather than just captioning what it sees.
Where it didn't move the needle at all: our Category 10 judgment tests - the ones designed to see whether the model would push back on ethically dodgy requests like fabricating an ROI figure or mimicking a competitor's landing page structure closely enough to skirt copyright. Both models refused or flagged the issue appropriately, every time. That's worth knowing too. You're not buying better ethics with the more expensive model. You're buying more horsepower applied to legitimate work.
Route tasks based on structural geometry, not arbitrary hype.
Bounded Execution
Single documents, standard asset optimization briefs, cold sequences, and copy iterations under 2,000 words.
Forensic Synthesis
Multi-source matrix maps, deep chart coordinate audits, financial dependency arrays, and unassisted long-horizon loops.
What This Actually Means For Your Monday Morning - Practical Implications
Stop running the same prompt on every model and eyeballing which output "sounds better." That test tells you about writing style, and writing style converged across frontier models roughly a year ago. Nobody's paying premium rates for marginally better prose anymore.
Instead, audit your own team's actual task list and sort it into two buckets. Bucket one: single-document, well-bounded, sub-2,000-word outputs - emails, single landing pages, short social copy, standard audits on one source. Keep these on Sonnet 5 or whatever your default model is. You will not see a meaningful quality difference and you're burning budget for nothing if you route them to Fable 5.
Bucket two: anything that requires holding more than roughly 10,000 words of source material in working memory simultaneously, anything involving visual data you'd otherwise have to manually transcribe into text first, and anything you currently do in multiple prompted stages because no model could hold the whole task coherently before. That's where Fable 5's export-ban-worthy autonomy actually pays for itself. Full competitor teardowns across a dozen sources. Multi-document forensic audits. Cohort-based financial modelling where you're reasoning through unit economics across several interacting variables rather than pulling one number off a spreadsheet.
One more practical note, and it's not optional: if you're running Fable 5 through the API for anything touching cybersecurity, biology, or chemistry topics - which, granted, is unlikely for most marketing use cases but not impossible if you're in a security or health-adjacent vertical - be aware the model can silently fall back to Opus 4.8 mid-session via safety classifiers Anthropic says trigger in under 5% of sessions. You'll get a response, just not from the model you thought you were paying for. Worth knowing before you build an automated pipeline around it.
Where This Is Actually Heading - The Forward View
The export ban episode is a preview, not an anomaly. Anthropic has said outright it's deepening collaboration with the US government on pre-release testing and information sharing going forward, and the company is working with Amazon, Microsoft, and Google to build a shared framework for assessing how dangerous a given "jailbreak" actually is before regulators have to make an eleven-day call on restricting a model globally. That framework doesn't exist yet in any mature form. Which means the next Mythos-class release could face the same disruption, and if your agency has built automated pipelines around a specific frontier model with no fallback plan, you learned an expensive lesson in early June that you should not need to learn twice.
For now, Claude Mythos 5 - the version without Fable's safety classifiers - remains restricted to vetted partners under Project Glasswing, and there's no public timeline for broader access. Fable 5 is, for the foreseeable future, as capable a model as most of us will get our hands on. Use that capability on the work that actually needs it.
TL;DR
Fable 5 didn't get export-controlled because it writes better LinkedIn posts. It got restricted because it can sustain complex, multi-step reasoning with minimal supervision - and that's precisely the capability most B2B marketing teams are failing to test for when they run the same generic prompts everyone else runs. Test bulk document synthesis, chart-reading, and unsupervised multi-stage execution. Don't test blog-post quality; that race ended already. And don't take Anthropic's benchmark percentages as gospel - test them against your own workload, because that's the only number that will actually affect your invoice.
Want to get ahead? Pull your last quarter's project list and tag every task by whether it needed more than one source document held in memory at once. If more than a third qualify, you have a real case for a Fable 5 line item in your tooling budget. If it's under 10%, save the money and put it toward the work a cheaper model already does fine.